How to Build Production-Ready AI Agents in 2025


Siddharth Sabale

Overview
This guide focuses on practical implementation of AI agents using current best practices and tools. We'll cover essential components and how to integrate them effectively.
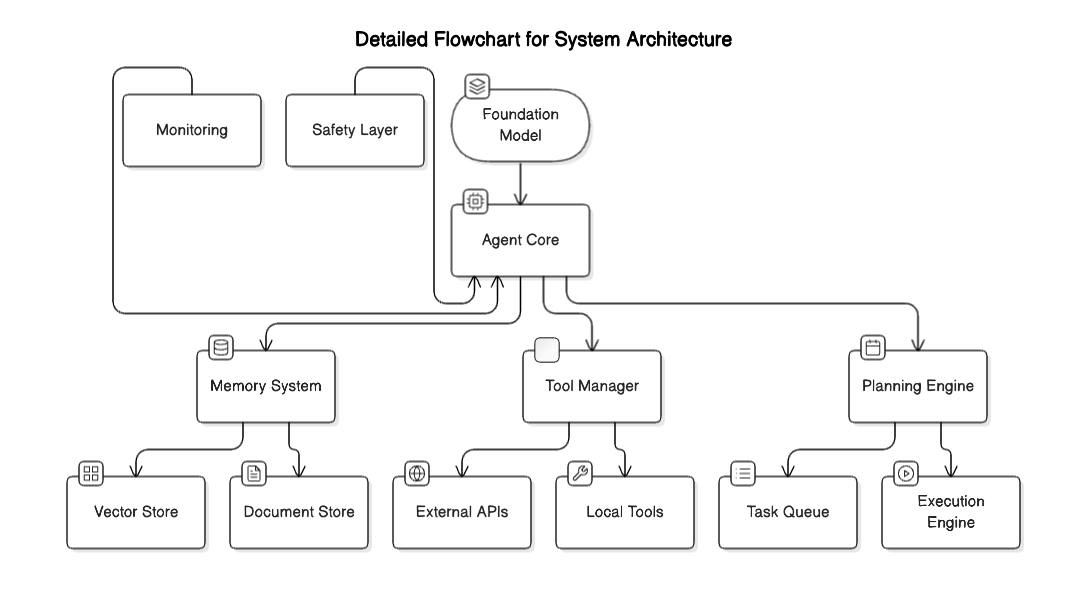
Foundation Model Selection
Choose your base model based on these criteria:
- Opus-class models (70B-100B parameters) for complex reasoning
- Sonnet-class models (7B-13B parameters) for faster inference
- Haiku-class models (1.5B-3B parameters) for edge deployment
Recommended options:
- Claude 3 Opus/Sonnet for hosted solutions
- Mistral or Llama family for self-hosted
- Gemini Pro for Google Cloud deployments
Key consideration: Balance between capability and latency. Most production systems use Sonnet-class models with occasional calls to Opus-class models for complex reasoning.
Opus-Class Models (70B-100B Parameters)
These powerhouse models form the backbone of complex reasoning systems. Claude-3 Opus and GPT-4 lead this category, offering unparalleled understanding of nuanced instructions and context. While they command higher computational resources, their superior reasoning capabilities make them ideal for tasks requiring expert-level analysis, creative problem-solving, and handling ambiguous scenarios. Typical response times range from 2-5 seconds, with costs around $0.01-0.03 per 1K tokens.
Sonnet-Class Models (7B-13B Parameters)
Models like Claude-3 Sonnet and Mistral Medium strike an optimal balance between performance and resource efficiency. These models excel at standard business operations, customer service, and content generation tasks. Their architecture enables rapid deployment with reasonable hardware requirements, making them suitable for production environments where cost-efficiency is crucial. Response times typically fall between 500ms-1.5s.
Haiku-Class Models (1.5B-3B Parameters)
Designed for edge deployment and rapid response scenarios, models like Claude-3 Haiku and Phi-2 offer impressive performance in lightweight packages. Their compact architecture enables deployment on mobile devices and edge servers while maintaining acceptable accuracy for basic tasks. These models shine in applications requiring sub-100ms response times and minimal resource consumption.
Integration Patterns
Direct API Integration
Modern API integration patterns emphasize resilience and efficiency. Implement sophisticated retry mechanisms with exponential backoff, maintain connection pools for optimal resource utilization, and leverage streaming responses for real-time applications. Build robust error handling that gracefully manages rate limits, temporary outages, and varying response times.
Self-Hosted Deployment
When deploying models on-premises, containerization with GPU support is essential. Implement load balancing across multiple instances to maintain consistent performance under varying load. Utilize model quantization techniques to optimize memory usage while maintaining acceptable inference quality. Regular performance monitoring and automated scaling ensure reliable operation.
Memory Architecture
Working Memory (Short-term)
1. Implementation Options
Redis with RedisJSON
Redis combined with RedisJSON provides blazing-fast in-memory data storage with JSON document support. This combination is particularly powerful for AI agents as it enables structured data storage with sub-millisecond access times. The RedisJSON module allows for native JSON operations, making it ideal for storing and manipulating complex nested data structures that represent agent states and intermediate computations.
PostgreSQL with pgvector
PostgreSQL with the pgvector extension offers a robust solution for storing and querying vector embeddings alongside traditional relational data. This setup enables sophisticated similarity searches while maintaining ACID compliance. The integration provides powerful indexing capabilities through IVFFlat and HNSW algorithms, making it suitable for production environments where data consistency is critical.
MongoDB with vector search
MongoDB's vector search capabilities provide a flexible, schema-less approach to storing agent memory states. Its distributed architecture enables horizontal scaling across multiple nodes, while the vector search functionality allows for efficient similarity-based retrieval of memories. The platform's aggregation pipeline enables complex memory processing and filtering operations at scale.
2. Key Features
TTL-based cleanup
Time-To-Live (TTL) mechanisms automatically manage memory lifecycle by removing outdated or irrelevant information. This feature is crucial for maintaining system performance by preventing memory bloat. The cleanup process runs asynchronously, ensuring minimal impact on the agent's primary operations while maintaining memory freshness and relevance.
Priority-based retention
Intelligent memory management through priority scoring ensures that critical information persists while less important data is eligible for removal. The priority system considers factors such as recency, frequency of access, and relevance to current tasks. This approach optimizes memory usage by retaining the most valuable information for the agent's operations.
Fast vector similarity search
High-performance similarity search capabilities enable rapid retrieval of relevant memories based on semantic similarity. The system utilizes optimized indexing structures like HNSW (Hierarchical Navigable Small World) graphs to achieve logarithmic time complexity for nearest neighbor searches, making it practical for real-time agent operations.
Episodic Memory (Long-term)
1. Storage Solutions
Weaviate Vector Database
Weaviate provides a sophisticated vector search engine with automatic schema inference and GraphQL API support. Its modular architecture allows for custom modules that can enhance search capabilities with specific domain knowledge. The platform's peer-to-peer architecture enables seamless horizontal scaling while maintaining consistent performance across the cluster.
Milvus Implementation
Milvus offers a cloud-native vector database designed for massive-scale similarity searches. Its architecture separates computing and storage layers, enabling independent scaling of each component. The platform supports multiple index types and distance metrics, allowing for optimized search strategies based on specific use cases and data characteristics.
Pinecone Integration
Pinecone provides a fully managed vector database service with automatic scaling and optimization. Its architecture is specifically designed for machine learning applications, offering features like hybrid search combining vector similarity with metadata filtering. The service maintains consistent low latency even at high query volumes through sophisticated load balancing and caching strategies.
Qdrant Deployment
Qdrant delivers a vector similarity search engine with extensive filtering capabilities and payload support. Its rust-based implementation ensures high performance and memory efficiency. The platform offers flexible deployment options from embedded to distributed configurations, making it suitable for various scales of operation.
2. Data Organization
Hierarchical clustering
Advanced clustering algorithms organize memories into hierarchical structures based on semantic similarity and temporal relationships. This organization enables efficient navigation through memory spaces and supports both broad and focused memory retrieval. The clustering system dynamically updates as new memories are added, maintaining optimal organization for quick access.
Temporal indexing
Sophisticated temporal indexing mechanisms maintain chronological relationships between memories while enabling efficient time-based queries. This system supports both absolute and relative temporal references, allowing the agent to understand and reason about sequences of events and causal relationships in its experience history.
Relevance scoring
Complex relevance scoring algorithms evaluate memories based on multiple dimensions including recency, frequency of access, and contextual importance. This multi-factor scoring system enables precise memory retrieval based on current context and task requirements. The scoring mechanism adapts over time based on usage patterns and feedback from agent operations.
3. Maintenance
Regular reindexing
Automated maintenance routines periodically optimize index structures to maintain search performance as the memory store grows. This process includes reorganizing indices, updating statistics, and optimizing storage layouts. The reindexing operations are scheduled during low-usage periods to minimize impact on agent operations.
Data pruning strategies
Intelligent pruning mechanisms maintain optimal memory store size by removing redundant or obsolete information. The pruning process considers multiple factors including information value, access patterns, and storage constraints. Advanced algorithms ensure that critical information is preserved while maintaining system performance and resource efficiency.
Backup mechanisms
Robust backup systems ensure data durability through automated, incremental backups and point-in-time recovery capabilities. The backup strategy includes both hot and cold storage tiers, with automatic data lifecycle management. Recovery procedures are regularly tested to ensure system reliability and data preservation.
Tool Selection & Integration
Development Frameworks
LangChain Implementation
LangChain provides a robust framework for building AI agents with standardized interfaces for model integration, memory management, and tool usage. Its modular architecture enables rapid development while maintaining flexibility for customization. The framework includes built-in support for popular vector stores, document loaders, and common tools, significantly reducing development time.
AutoGPT Architecture
AutoGPT offers an autonomous agent framework focused on goal-oriented task completion. Its architecture excels at task decomposition and self-prompted execution, making it ideal for complex, multi-step processes. The system includes built-in memory management and tool integration capabilities, with extensive customization options for specific use cases.
Microsoft Semantic Kernel
This framework provides a sophisticated architecture for AI orchestration, offering deep integration with Azure services while maintaining platform independence. Its semantic memory system and skill management make it particularly suitable for enterprise applications requiring tight integration with existing systems.
Essential Tools
Vector Databases
Production-grade vector databases like Weaviate, Milvus, and Pinecone form the cornerstone of efficient memory systems. Each offers unique advantages: Weaviate excels at schema inference and GraphQL support, Milvus provides superior scaling capabilities, and Pinecone offers managed services with consistent performance guarantees.
Document Processing
Robust document processing pipelines combine OCR capabilities from Tesseract or Azure Computer Vision with text extraction tools like Unstructured. Implement intelligent document segmentation and classification to handle various formats while maintaining semantic coherence.
API Integration
Modern API integration requires sophisticated tools for rate limiting, authentication management, and response handling. Implement circuit breakers for external services, maintain detailed usage metrics, and build comprehensive error handling systems that gracefully degrade functionality when services are unavailable.
Planning & Execution
Use Tree of Thoughts for planning:
Task Decomposition
- Break complex tasks into subtasks
- Use LLM to generate action plan
- Validate against capabilities
Execution
- Async execution with background workers
- Redis or RabbitMQ for task queue
- Implement retry logic with exponential backoff
Safety & Monitoring
Safety Mechanisms
Content Filtering
Implement multi-layer content filtering systems that combine rule-based filters with ML models for toxicity detection. Build comprehensive prompt injection detection systems that identify and prevent potential attacks. Maintain regularly updated blocklists while implementing semantic analysis for context-aware filtering.
Output Validation
Develop robust output validation systems that check for hallucinations, inconsistencies, and potentially harmful content. Implement fact-checking mechanisms against known truths and maintain version control for model responses. Build comprehensive logging systems that track decision paths and validation results.
Authentication & Authorization
Implement sophisticated role-based access control (RBAC) systems that manage tool access and capability limits. Build comprehensive audit trails of all agent actions and decisions. Maintain separate development, staging, and production environments with appropriate access controls and monitoring.
Monitoring Systems
Performance Monitoring
Deploy comprehensive monitoring solutions combining Prometheus for metrics collection, Grafana for visualization, and custom dashboards for business-specific KPIs. Track response times, token usage, error rates, and system resource utilization across all components of the agent system.
Quality Assurance
Implement automated testing systems that regularly evaluate model outputs for quality and consistency. Build comprehensive logging systems that track all agent actions and decisions. Maintain separate monitoring for model performance, tool usage, and business outcomes.
Essential Resources
Development Tools
Version Control & CI/CD
Implement sophisticated version control systems using Git with branch protection rules and automated testing. Build comprehensive CI/CD pipelines that include automated testing, security scanning, and deployment validation. Maintain separate environments for development, staging, and production with appropriate access controls.
Testing Frameworks
Develop comprehensive testing suites that combine unit tests, integration tests, and end-to-end validation. Implement automated testing of model outputs, tool interactions, and system performance. Build regression testing systems that ensure new deployments maintain quality standards.
Monitoring & Analytics
Deploy robust monitoring solutions that track system health, model performance, and business outcomes. Implement comprehensive logging systems that enable detailed analysis of agent behavior and decision-making processes. Build custom analytics dashboards for tracking KPIs and system performance.
Resources
- Development Tools:
- LangChain or AutoGPT for agent framework
- LlamaIndex for memory management
- Weights & Biases for experiment tracking
- Testing:
- Unit tests for tool integrations
- Integration tests for workflows
- Evaluation suite for agent responses
Cost Optimization
Typical cost breakdown:
- Foundation model: 60-70%
- Vector storage: 15-20%
- Tool API calls: 10-15%
- Infrastructure: 5-10%
Cost reduction strategies:
- Cache common queries
- Implement token optimization
- Use smaller models for simple tasks
- Batch similar requests
Next Steps
Start with
- Set up development environment
- Implement basic agent loop
- Add essential tools
- Deploy monitoring
- Then add:
- Advanced memory systems
- Custom tools
- Safety layers
- Performance optimization
- Finally:
- Scale horizontally
- Implement caching
- Add redundancy
- Optimize costs
For detailed implementation examples, check:
- GitHub: github.com/langchain-ai/langchain
- LangChain docs: python.langchain.com
- Claude API docs: docs.anthropic.com
Remember: Start simple, test thoroughly, and scale gradually based on actual usage patterns.
Ready to Build Your AI Agent?
Transform your business with a custom AI agent tailored to your needs. At Byteplexure, we specialize in developing production-ready AI solutions that drive real business value.
Whether you're looking to:
- Build a custom AI agent from scratch
- Integrate AI capabilities into existing systems
- Scale your current AI infrastructure
- Optimize costs and performance
Let's discuss how we can help you achieve your AI goals.
📧 Contact us at hello@byteplexure.com to:
- Schedule a technical consultation
- Get a personalized solution design
- Start your AI agent development journey
Take the first step toward building your next-generation AI solution today.
Looking for reliable development partners? Check out our curated list of offshore software development companies.




